Outline of the vocabulary
This documents specifies splog, a vocabulary to log data processing and sharing events that should comply with a given consent provided by a data subject. We also model the consent actions related to consent giving and revocation.
This specification was published by the SPECIAL H2020 EU project. It is not a W3C Standard nor is it on the W3C Standards Track. For additional details see the SPECIAL Deliverable D2.7 [[SPECIALD27]].
To participate in the development of this specification, please contact Sabrina Kirrane, the scientific coordinator of the SPECIAL H2020 EU project. If you have questions, want to suggest a feature, or raise an issue, please send a mail to the special-contact@ercim.eu contact.
The European General Data Protection Regulation defines a set of obligations for personal data controllers and processors. Primary obligations include: obtaining explicit consent from the data subject for the processing of personal data, providing full transparency with respect to the processing, and enabling data rectification and erasure (albeit only in certain circumstances). At the core of any transparency architecture is the logging of events in relation to the processing and sharing of personal data. The logs should enable verification that data processors abide by the access and usage control policies that have been associated with the data based on the data subject’s consent and the applicable regulations.
The SPECIAL Policy Log Vocabulary is focused purely on the representation of such logs using the W3C RDF (Resource Description Framework) standard and published following the principles of linked data.
At the heart of a log is a set of log entries organized along the privacy-aware content they relate to, together with associated metadata. The SPECIAL Policy Log Vocabulary makes extensive use of the Usage Policy Language Ontology, defined within the SPECIAL H2020 EU project.
The SPECIAL Policy Log vocabulary in turn builds upon the following existing RDF vocabularies:
This document describes the SPECIAL Policy Log. It is aimed at people wishing to publish data processing and sharing events that must comply with a privacy policy in RDF as well as consent-related activities (acquisition and revocation). Mechanics of cross-format translation from other formats are not covered here.
The namespace for the SPECIAL Policy Log Vocabulary is http://purl.org/specialprivacy/splog#. We write triples in this document in the Turtle RDF syntax [[TURTLE]] using the following namespace prefixes:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX spl: <http://specialprivacy.ercim.eu/langs/usage-policy#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX prov: <http://www.w3.org/ns/prov#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
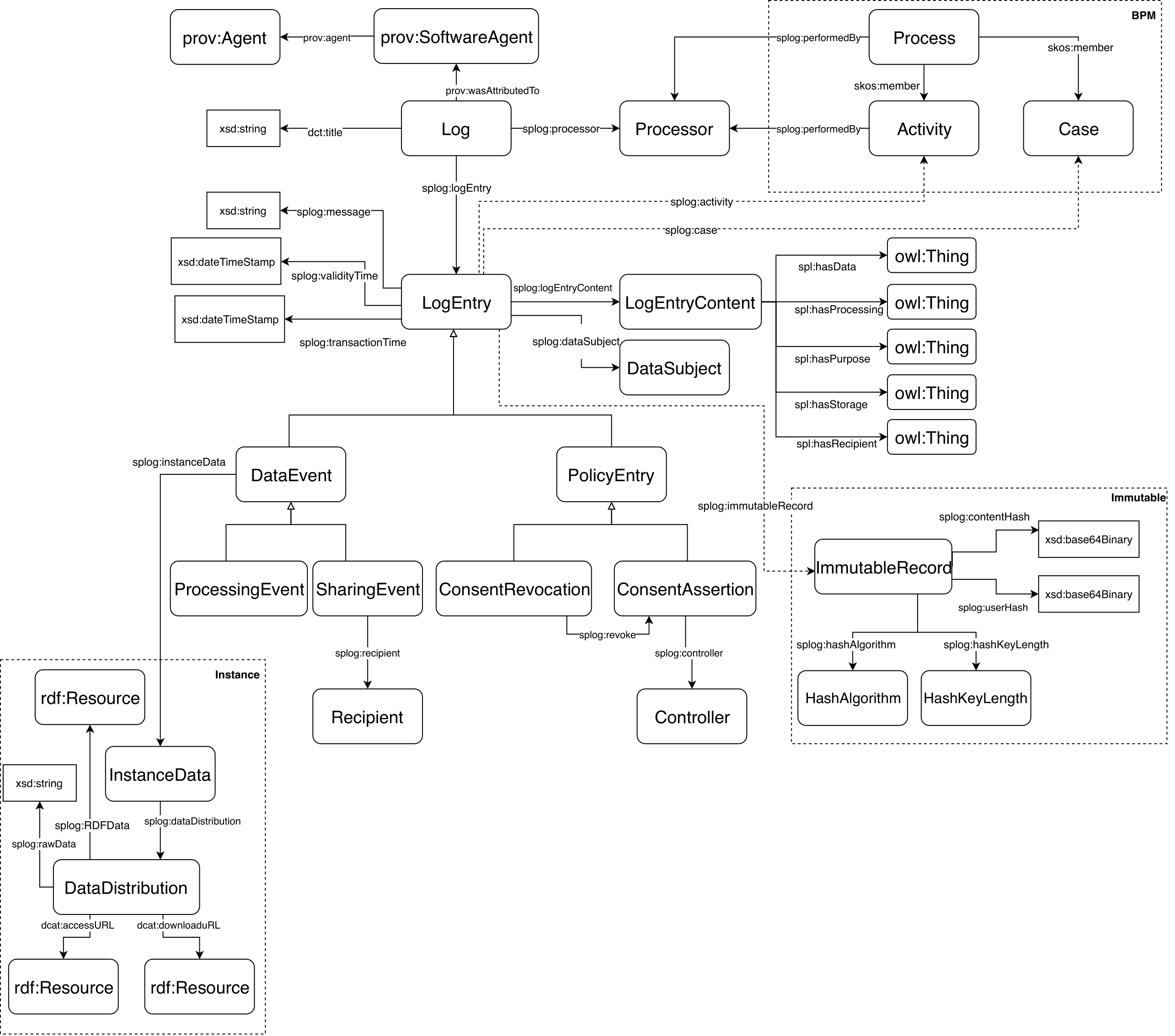
A Log is a collection of data that records data processing and sharing events as well as consent-related activities (acquisition and revocation). The data in a Log can be roughly described as belonging to one of the following categories:
splog:Processor instance) whose service is logged, related via the splog:processor property (a subproperty of prov:agent).splog:logEntry property (a prov:wasGeneratedBy subproperty) to point to each of the entry in the log.splog:eventGroup (a subproperty of splog:event).
Log entries contain information about processing and sharing events associated to data subjects, as well as actions related to the consent provided (or revoked) by data subjects. These different types of entries are represented in our model with a classification of log entries, i.e., a hierarchy of classes. Thus, a LogEntry has two main types (subclasses), PolicyEntry and DataEvent, described as follows:
PolicyEntry:ConsentAssertion specifying a consent provided by a data subject to a Controller (linked with a splog:controller property), and ConsentRevocation, denoting the revocation of a given consent. Note that, in principle, we assume that a consent provided by a data subject replaces any previous consent, hence consent updates are implicit. Nonetheless, companies may wish to explicitly record a revocation entry pointing to the revoked consent, thus we include this capability via the splog:revoke property in our model. This latter may facilitate consent tracking and consent versioning. DataEvent:Recipient can be specified, via the splog:recipient property.LogEntry as a whole. Metadata is described in Section 7.splog:dataSubject property (a prov:wasAssociatedWith subproperty) pointing to the appropriate splog:DataSubject involved in the entry. For the sake of simplicity, we assume that an entry is related to a single data subject, but multiple data subjects MAY be specified using multiple splog:dataSubject properties. Note that in case of anonymized logs, no subject can be specified. splog:logEntryContent property, pointing to the actual splog:LogEntryContent. This is described in Section 5splog:validityTime property (subproperty of prov:atTime). Note that this is based on the notion of considering instaneous events for the log entries. For the sake of log preservation, the log entry SHOULD also reflect the time in which the log was recorded, using splog:transactionTime (a dct:issued subproperty).splog:message of the log representing a human-friendly text.splog:InmutableRecord of its contents.Activity, via the splog:activity property, and the concrete Case, via the splog:case property. Activities and Cases are members of a splog:Process, specified with skos:member. Both Activities and Cases can point to the involved splog:Processor, via the splog:performedBy property.
This example provides a quick overview of how the SPECIAL Policy Log vocabulary might be used to represent a log. First, the log description:
where eg:log1 is an instance of a Log, and eg:TrackingSystemR2D2 is a software within the eg:beFitInc company.
Then, we include a new entry in the log, which is a processing event. The collection of the new position took place on 3rd January at 13:20 (i.e. validity time) and the event was recorded few seconds later (i.e. transaction time).
where eg:logEntry1 is an instance of a ProcessingEvent, eg:user1 is the data subject related to the event, eg:iRec1 represents the inmutable version of the event and eg:content1 points to the actual content, defined as follows:
In turn, the immutable Record can be defined as the hash of the content and the data subject, which can be kept in a different ledger or Knowledge Base, together with the definition of the hash algorithm:
The log entry content is represented by the splog:LogEntryContent Class, which is a rdfs:subClassOf the SPECIAL spl:Authorization. This way, event content and data policy authorizations can be checked for compliance.
spl:hasDataeg:dataItem1 a svd:Location, without actual coordinates.spl:hasProcessingspl:hasPurposespl:hasStoragespl:hasRecipient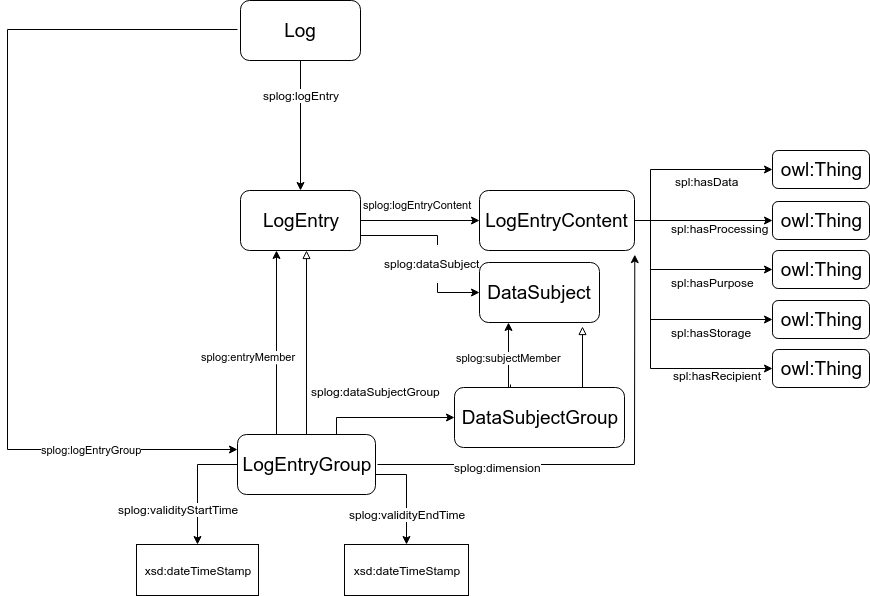
An log entry group is a subclass of a log entry, containing information about one or more log entries in order to support presentation and processing. The data in a log entry group can be roughly described as belonging to one of the following kinds:
splog:validityStartTime and splog:validityEndTime properties (subproperties of prov:startedAtTime and prov:endedAtTime), denoting the validity time. For the sake of log preservation, the entry SHOULD also reflect the time in which the log was recorded, e.g using the splog:transactionTime property (a dct:issued subproperty).splog:dimension property (a subproperty of splog:logEntryContent), pointing to a particular splog:LogEntryContent. splog:dataSubjectGroup property (a prov:wasAssociatedWith subproperty). This property refers to a splog:DataSubjectGroup instance that groups all the splog:DataSubject instances, using skos:broader. splog:member property (a skos:broader subproperty).Logs, log entries and log entry groups entries SHOULD be marked up with metadata to support presentation and processing. Dublin Core Terms [[DCTERMS]] SHOULD be used for representing the key metadata annotations commonly needed for Logs.
The recommend core set of metadata terms is:
dct:title - may be same as rdfs:labeldct:description - may be same as rdfs:commentdct:issueddct:modifiedAdditional metadata terms can be used for describing policy logs.
In the log model, we assume that the description of entries coming from different systems can be merged and integrated together in a single store, which will potentially serve transparency and compliance mechanisms.
In certain scenarios, named graphs can be used to encapsulate logs before integrating entries coming from different subsystems. For example, let us assume a gym company ViennaGym, referred to with the namespace viennagym, makes offers based on a mutual sharing policy with the previous company beFitInc. The following example builds upon the previous gathering event (see Examples 1 and 2) and shows the integration with a marketing event from ViennaGym. First, the data item is gathered by beFitInc (previous example), then it is shared between the company beFitInc and ViennaGym, and finally this latter uses the data to provide marketing advertising. These series of events is encapsulated in three graphs eg:tracking, eg:sharing, and viennagym:marketing respectively. We make use of the TriG [[TRIG]] syntax to extend Turtle with named graphs.
In principle, the main objective of the SPLog is to record data processing and sharing events, together with policy-related events (consent assertion and revocation), keeping the actual (instance) subjects’ data in a different ledger. However, SPLog additionally provides an optional instance module (a) to store such instance data, or (b) to refer to (a service or API) where the instance data can be located. In the following, we provide details and examples on the potential use of this vocabulary for these two cases. In both cases, we consider a splog:InstanceData class (a subclass of dcat:Dataset) associated to a splog:DataEvent log entry via the splog:instanceData property. Then, the instance data can be served in different splog:DataDistribution (subclass of dcat:Distribution), e.g. one distribution stored in raw CSV data and one in JSON data. Combining storing and referenced data is also possible.
A first possibility is to store the actual data in the log. For instance, BeFit may decide to store in the log both the data collection event and (a copy of) the actual collected data of Sue’s Befit device. Note that physically storing the instance data in the log implies that the log contains (even more) sensitive data. Thus, in general, it is not recommended that the instance data are kept on a public ledger (such as blockchain), as a security breach or a future hash break would expose the actual data. In addition, similarly to the previous case of the log entries, an immutable ledger would prevent the controller of deleting or rectifying the data (as it is required), hence cryptographic deletion mechanisms must be in place for the actual data.
The SPLog vocabulary provides two ways of storing instance data, (a) storing raw data (e.g. JSON, CSV, etc.) or (b) storing the semantic representation of the data (i.e. RDF data).
Storing raw data. In this case, the splog:DataDistribution contains the raw data itself, using the splog:rawData property and further described with additional properties such as dct:format media type or dcat:byteSize. The following is an example of a raw distribution in CSV, showing the collection of location data from Sue.
Storing RDF data. In case the data is actually RDF data, the concrete resource (e.g. an RDF resource or named graph) can be specified via splog:RDFData. The following is an example of storing a distribution in RDF, showing the collection of heart rate data from Sue.
In this particular case, the instance data is located externally. Note that a first possibility is that the distribution makes use of the aforementioned splog:RDFData property, but the resource itself is external. In that case, the data can be retrieved with a standard Linked Data dereferenciation. In general, as explained, SPLog provides access to external data via splog:downloadURL (subproperty of dcat:downloadURL), typically described via a dct:format media type, or splog:accessURL (subproperty of dcat:accessURL), when the data cannot be directly downloaded but there is an access point (e.g. landing page, feed, SPARQL endpoint). The following is an example of a reference to a JSON storing the collection of heart rate data from Sue at the given time.
The work is supported by the European Union's Horizon 2020 research and innovation programme under grant 731601 (SPECIAL).